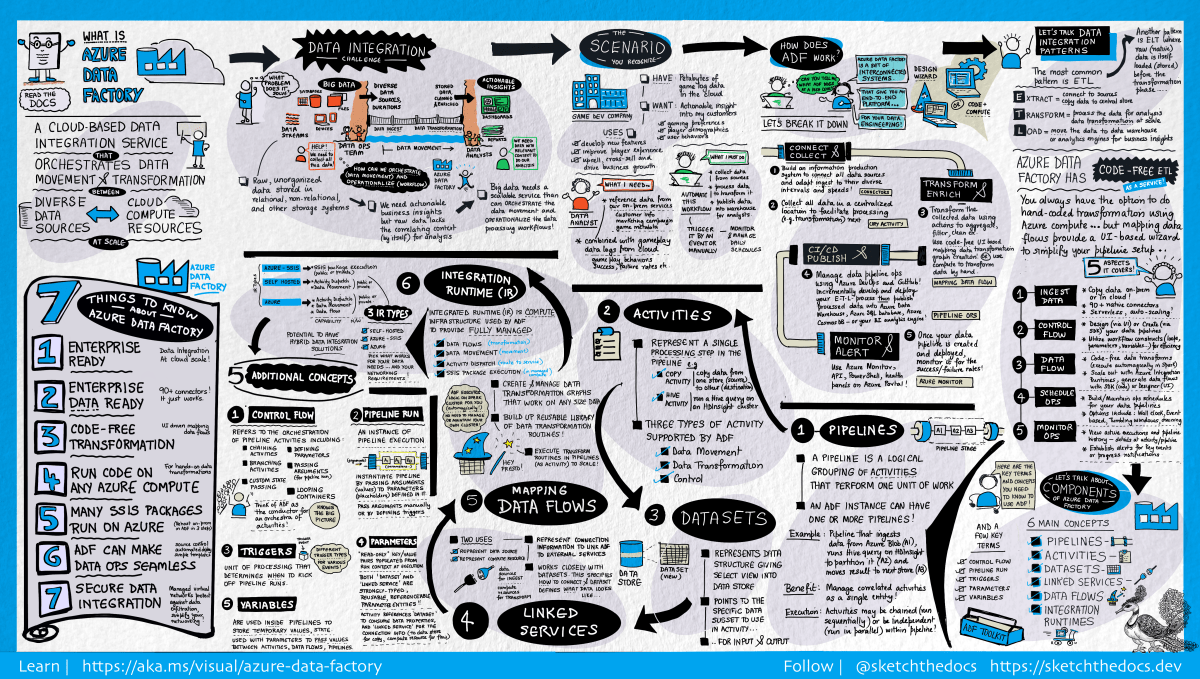
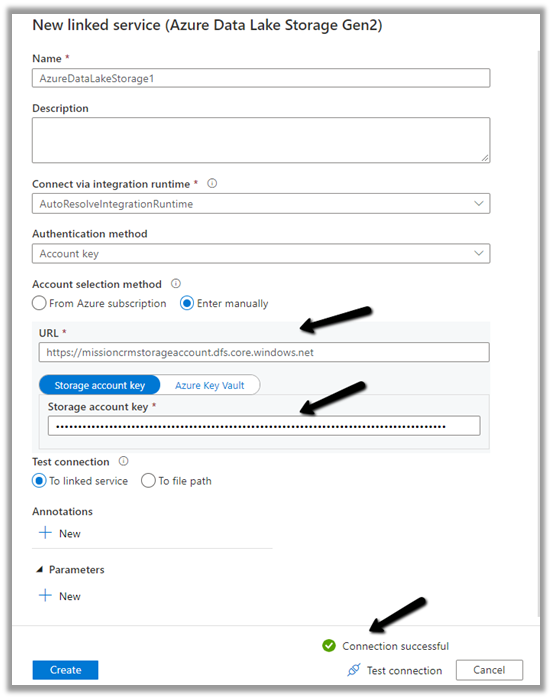
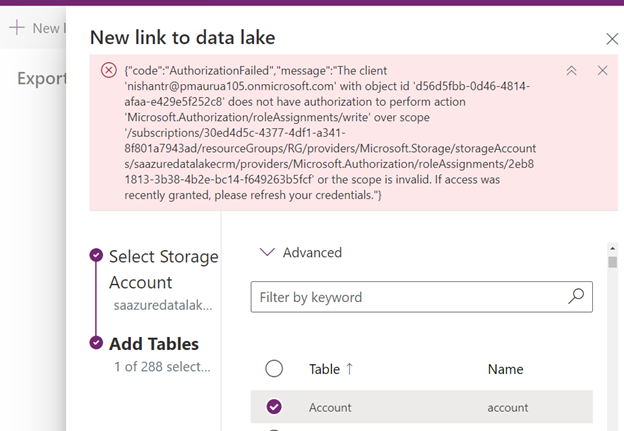
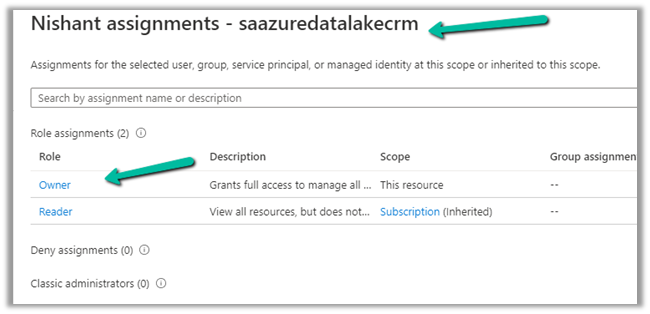
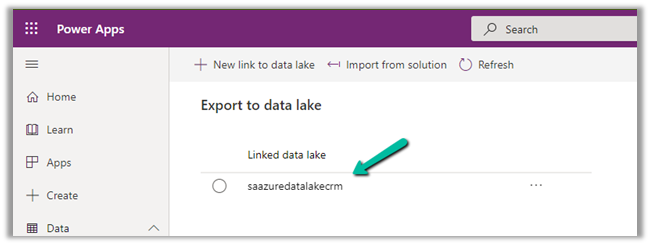
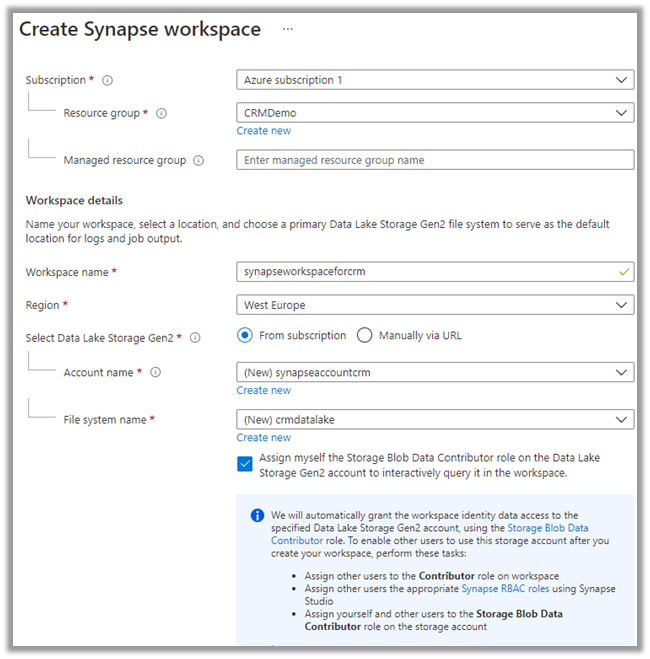
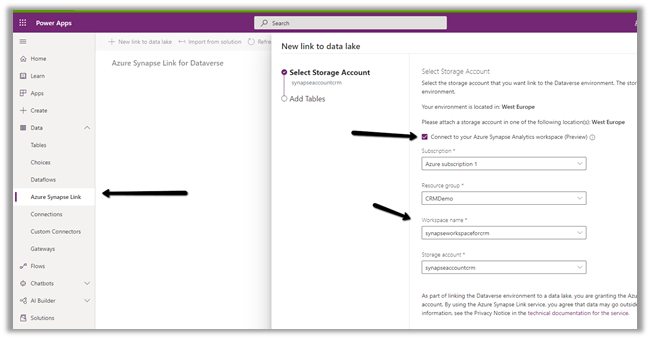
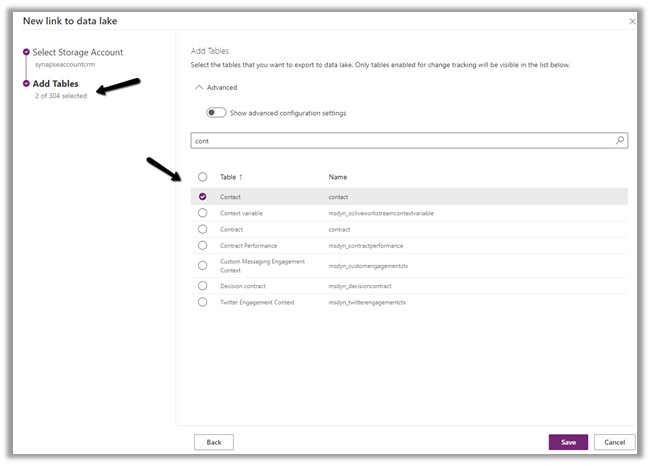
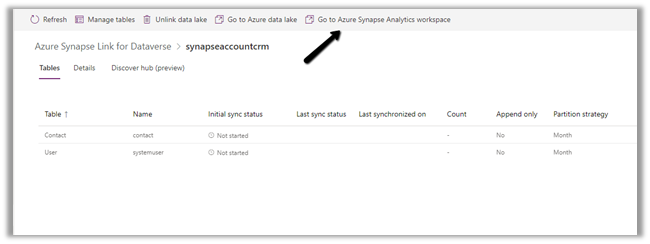
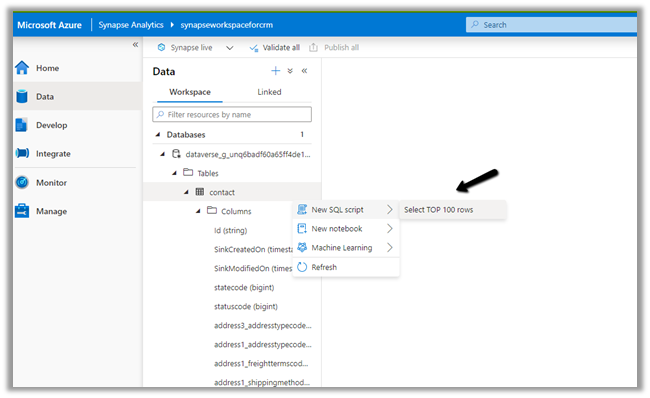
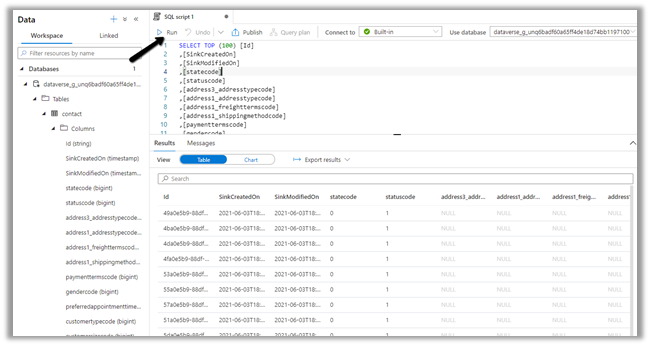
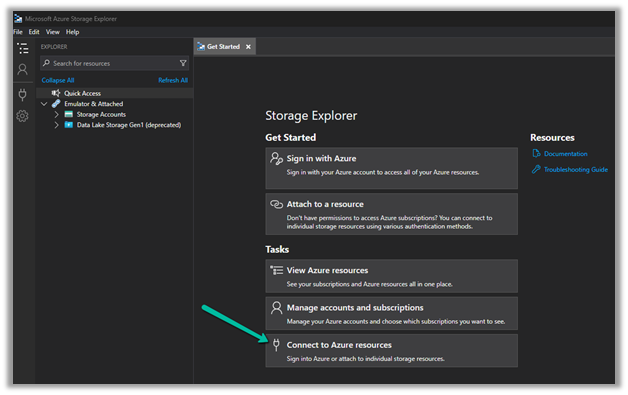
We can access our environment’s storage using a SAS token.
Download – Azure Storage Explorer – https://azure.microsoft.com/features/storage-explorer/#overview
Select Connect to Azure resources option
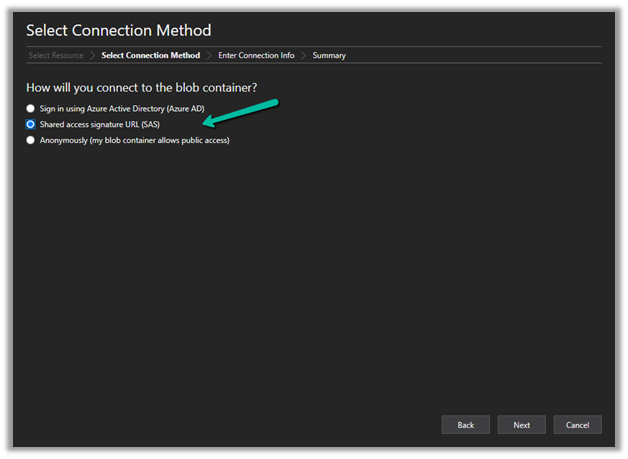
Select ADLS Gen2 container or directory for the Azure storage type.

Select the Shared access signature URL for the connection
To get the SAS URL – https://[ContainerURL]/CDS?[SASToken],
we need ContainerURL and SASToken.
To get Container URL use the below link –
ContainerURL = <a href="https:///api/data/v9.1/datalakefolders”>https://<EnvironmentURL>/api/data/v9.1/datalakefolders
In our case – https://mycrm2022.crm.dynamics.com/api/data/v9.1/datalakefolders
The containerendpoint = https://aeth2b4c5907361d483c9641.dfs.core.windows.net/aeth-b986098f-1315-45cc-b8e6-61c5a1a1631a
Copy the value of containerendpoint (ContainerURL)
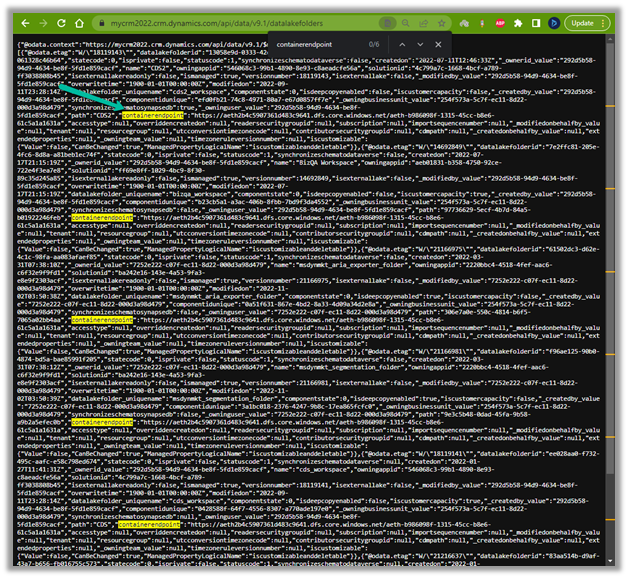
Navigate to the below URL by replacing the value of the Environment URL and Container URL
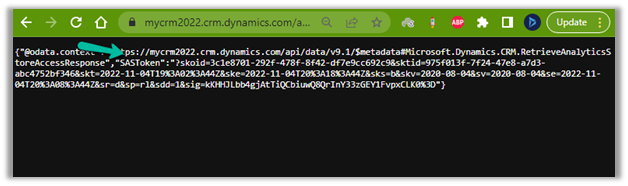
<a href="https:///api/data/v9.1/RetrieveAnalyticsStoreAccess(Url=@a,ResourceType=’Folder’,Permissions=’Read,List’)?@a=’/CDS”>https://<EnvironmentURL>/api/data/v9.1/RetrieveAnalyticsStoreAccess(Url=@a,ResourceType=’Folder’,Permissions=’Read,List’)?@a='<ContainerURL>/CDS’
i.e.
to get the SAS token (the SAS Token will expire after 1 hour)
Construct the SAS URL which we will use in the Azure Explorer’s connection info <a href="https:///CDS?https://<ContainerURL>/CDS?<SASToken>
https://aeth2b4c5907361d483c9641.dfs.core.windows.net/aeth-b986098f-1315-45cc-b8e6-61c5a1a1631a/CDS?skoid=3c1e8701-292f-478f-8f42-df7e9cc692c9&sktid=975f013f-7f24-47e8-a7d3-abc4752bf346&skt=2022-11-04T19%3A02%3A44Z&ske=2022-11-04T20%3A18%3A44Z&sks=b&skv=2020-08-04&sv=2020-08-04&se=2022-11-04T20%3A08%3A44Z&sr=d&sp=rl&sdd=1&sig=kKHHJLbb4gjAtTiQCbiuwQ8QrInY33zGEY1FvpxCLK%03D0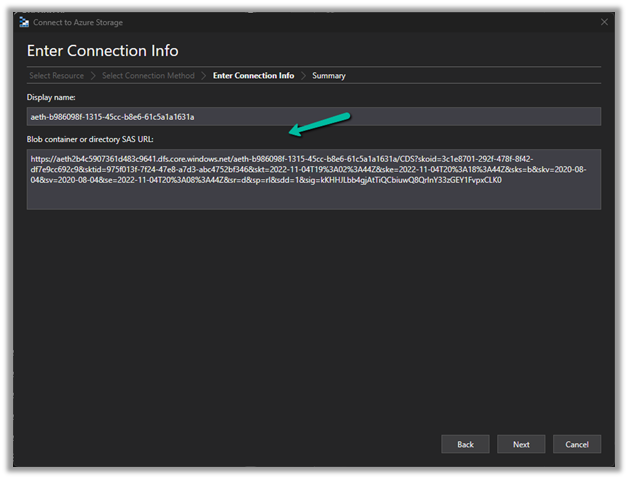 Now we have access to the storage
Now we have access to the storage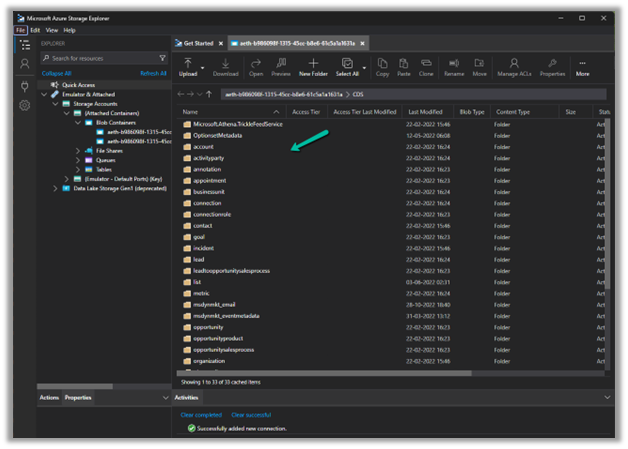
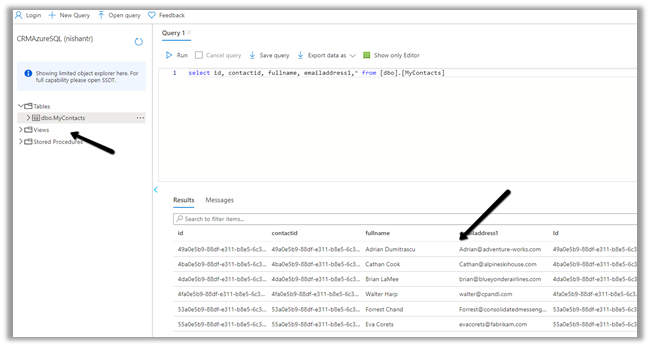
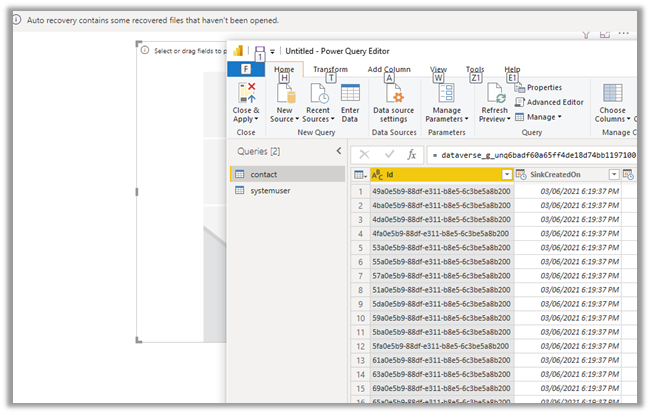
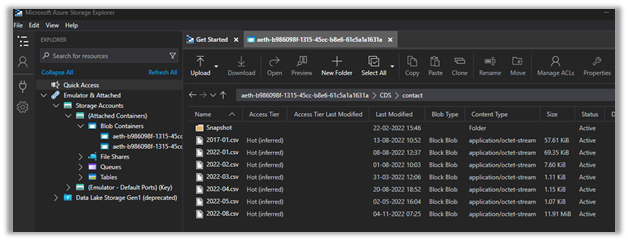
Here we have opened the contact folder just as an example
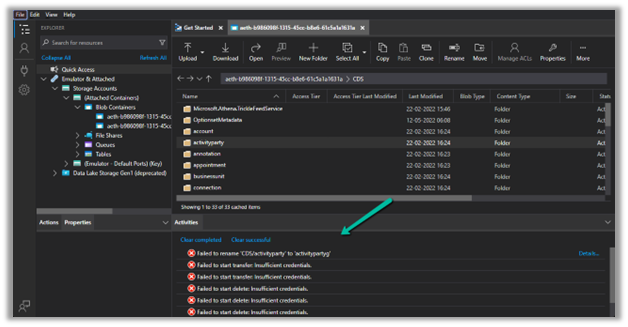
We only have read-only access, any other access like delete, rename, upload, etc. will fail
Get all the details here – https://learn.microsoft.com/en-us/power-platform/admin/storage-sas-token
Hope it helps..