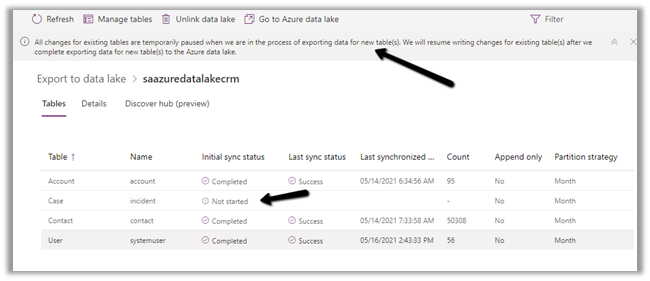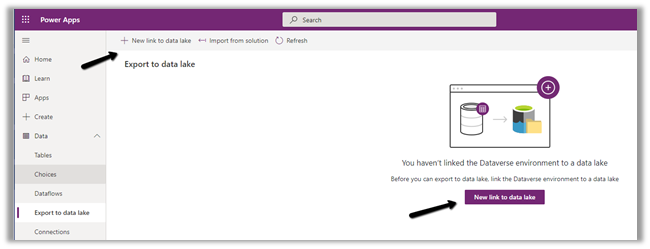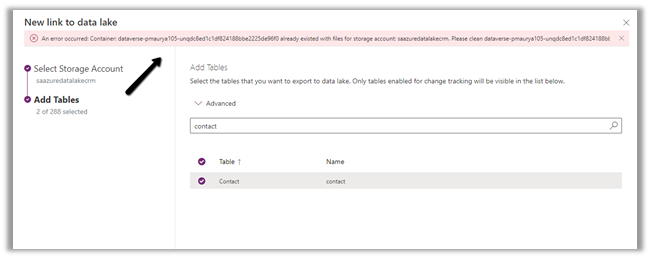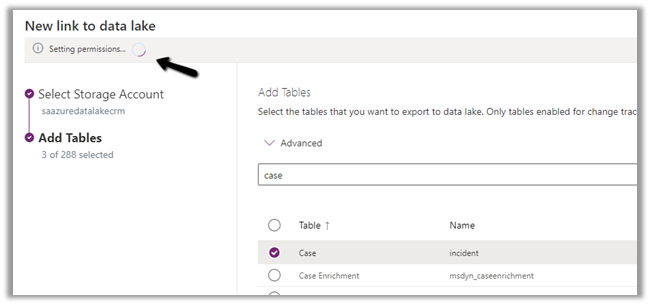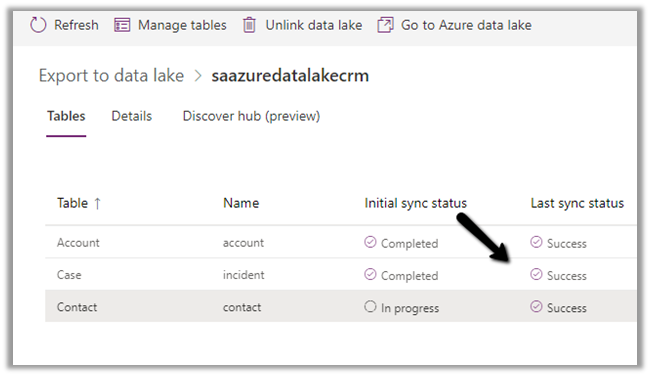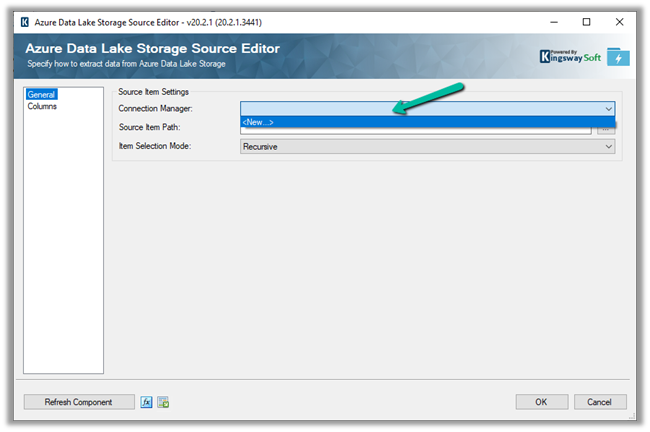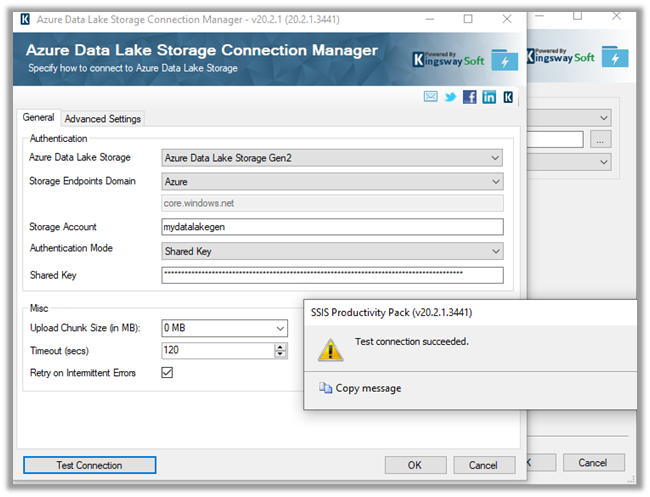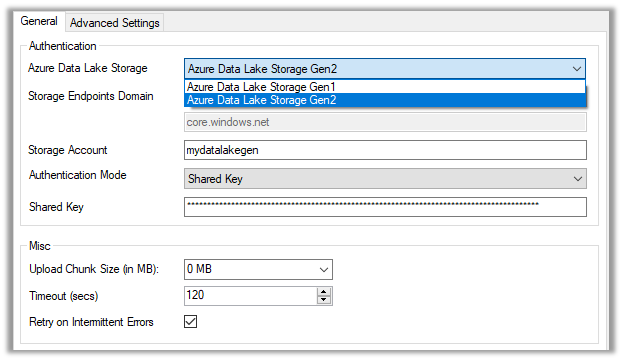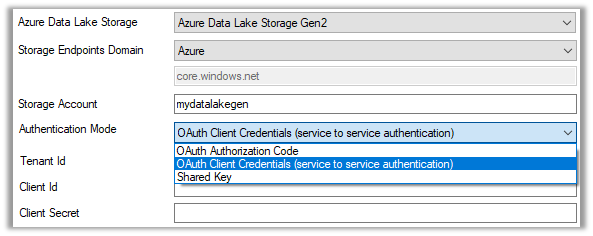
The Export to Data Lake service now has some Advanced configuration settings available.
To learn more on Export to Data Lake service
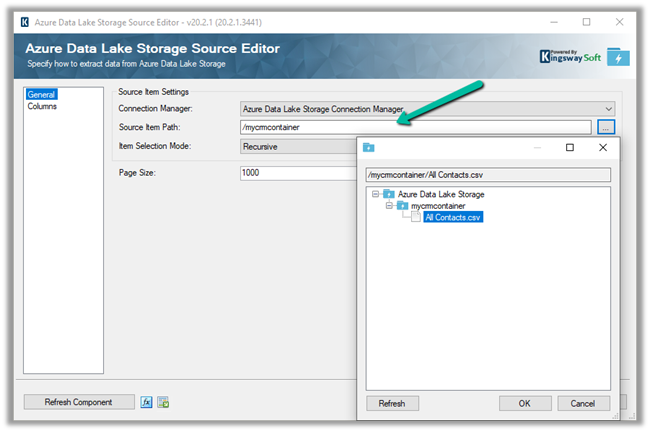
The new settings allow us to configure how the DataVerse / CRM table data is written to Azure Data Lake.
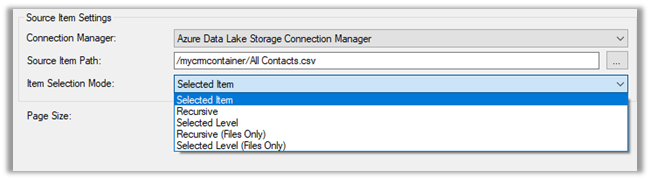
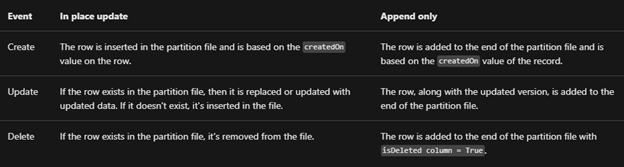
- In-Place update or upsert (default)
- Append Only
With the in-place update, the default setting, the file will contain the full data set, and any update in the source will update the same in the synced CSV file or the data partition, similarly, any record deleted will delete the row from the data partition, unlike Append Only where a new row will be added in case of both update and delete.
For huge volume of data, Microsoft recommends opting for Append only mode. This mode is also preferable when an organization wants to incrementally review the changed data.
The other option is to define the data partition strategy.
- By Month (default)
- By Year
With this option, files generated are partitioned by either year or more granular month-wise, which can be specified per-table basis.
Microsoft recommends Monthly partition if data volume is high.
Now, let us see it in action.
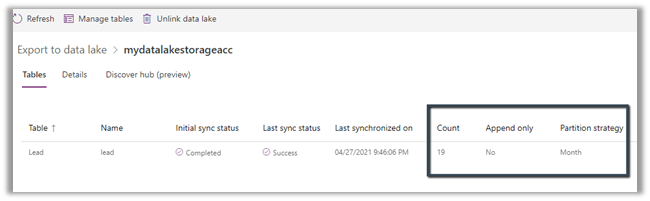
For the Lead table, we haven’t selected the option for advanced configuration settings and are going by default.
- Append Only – No
- Partition Strategy – Month
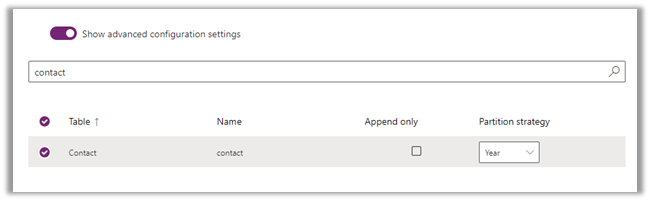
For contact, we have enabled the advanced configuration settings and opted for Partition Strategy as Year.

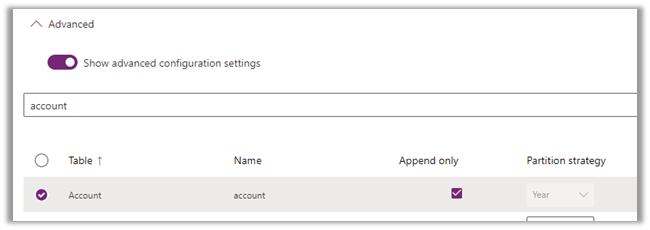
For Account , we have opted for Append Only as true, for which the Partition strategy option is disabled and set as Year.

The final configuration à
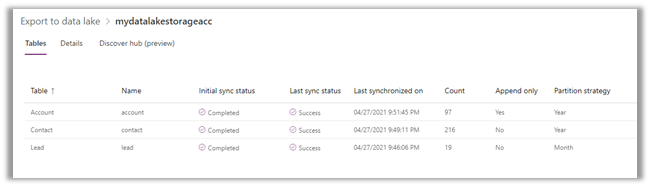
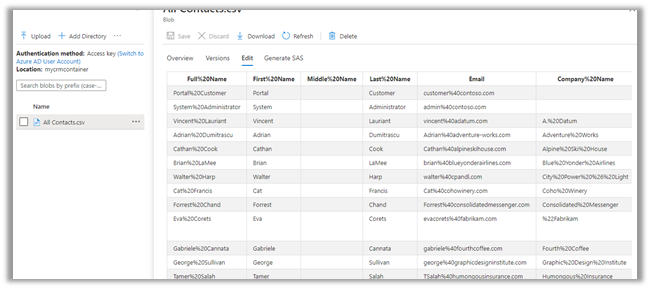
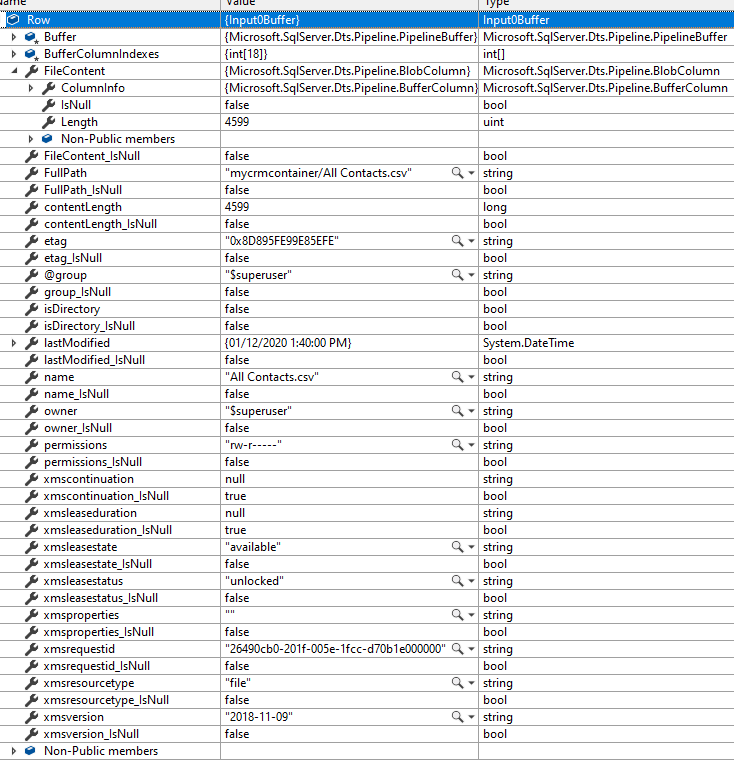
Within the container inside the Storage Account, we can see corresponding folders created per table/entity along with model.json as shown below.
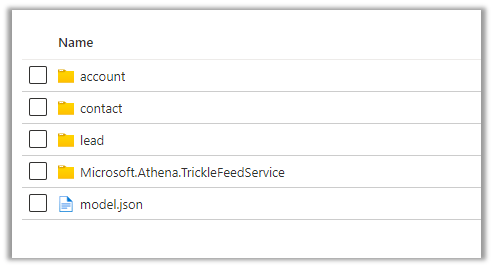
Let us explore the Lead folder –
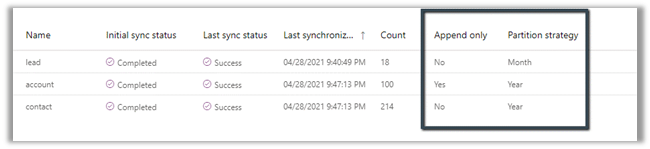
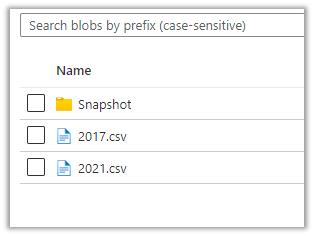
We can see 2 CSV created with format YYYY-MM.csv i.e. having the month part in it because we had specified Partition Strategy as Month i.e. the default value.

For Contact and Account, the Pattern Strategy was Year, so we have files generated in format YYYY.csv
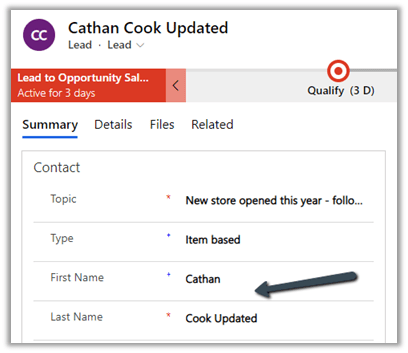
Let us update one of the lead records by appending ‘Updated’ in the last name field.
After the successful sync,
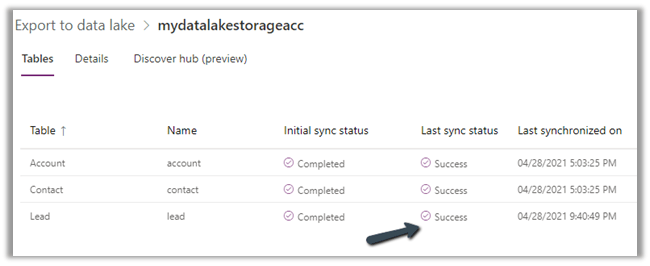
we can see the record updated in the .csv / partition.
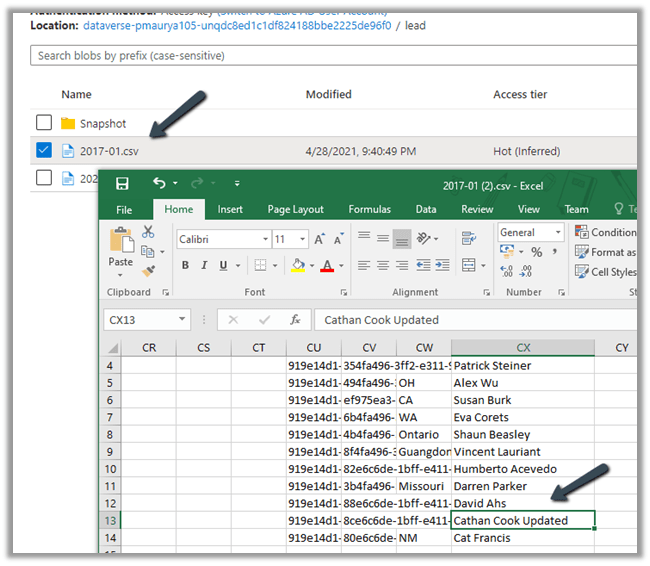
The same is the case with the contact record.
Now let us update an account record, it had Append Only specified as Yes.
Here we update the Account Name field from Litware to Litware Updated.
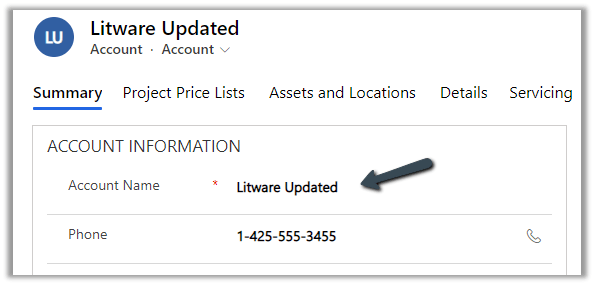
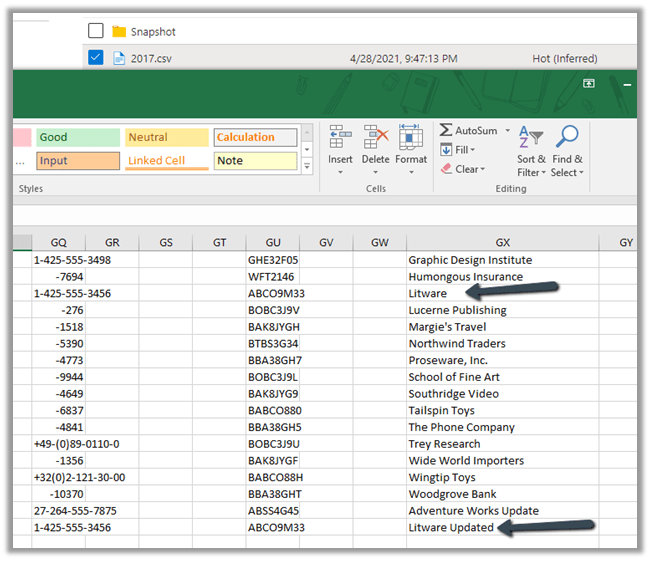
After the sync

We can see a new row appended with the updated record along with the original record.
Let us delete the same account record
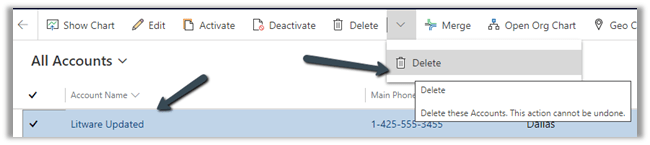
As expected, being Append Only mode, we can see a new row added for the Litware record.
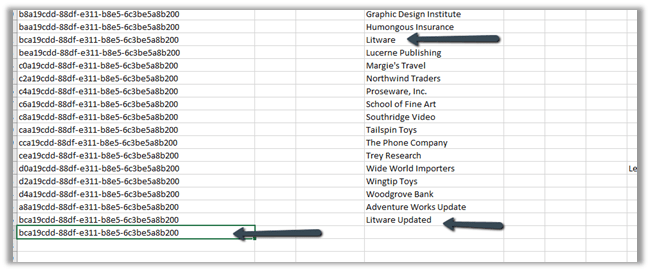
We have 2 additional rows apart from the original row, one created for update and the other for delete action.
Export to Data Lake service is Microsoft’s recommended way of synchronizing Dataverse Data with external storage, and we can see them continuously investing and adding enhancements to it.
Get all the details here –
Hope it helps..