[Visual Guide to Azure Data Factory - https://acloudguru.com/blog/engineering/a-visual-guide-to-azure-data-factory]
Using the new Azure Data Factory pipeline template – Copy Dataverse data from Azure Data Lake to Azure SQL – we can now easily export the Dataverse data to Azure SQL Database.
Check other posts on Azure Data Factory
Select Pipeline from template option inside the Data Factory

Search for Dataverse and select the Copy Dataverse data from Azure Data Lake to Azure SQL template
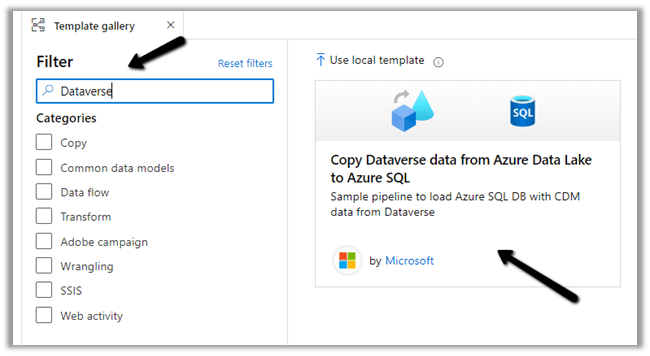
Let us specify the User Inputs required by the template – i.e. Azure SQL Database and the Data Lake Storage.

First we have created the linked service for the Azure SQL Database.

We’d use it to connect to the below table MyContacts.

Similarly create a linked service to Azure Data Lake Gen 2, which holds our Dataverse data.

Get the URL from the Container’s property. (replace blob with dfs in the URL)

To get the storage account key, select Access Keys >> Show Keys >> Copy the Key for the Storage Account.

Here we have already configured Azure Synapse Link for Dataverse

Now as we have defined the User Inputs, select Use this template.
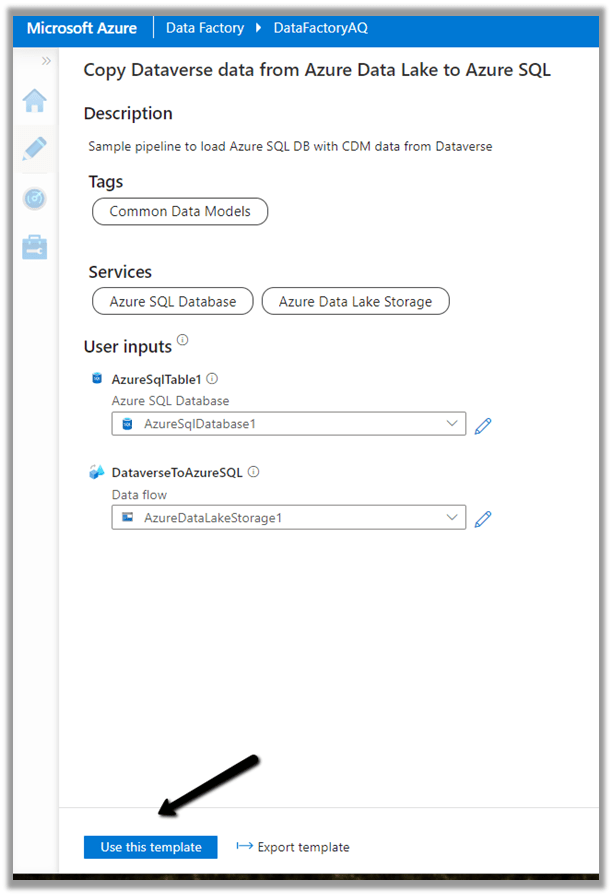
Navigate to the data flow created – DataverseToAzureSQL

Select our source ADLS and check and configure its properties.
Source Settings
Here we have the Inline dataset type set to Common Data Model and the Linked service is the AzureDataLakeStorage1 we created earlier.
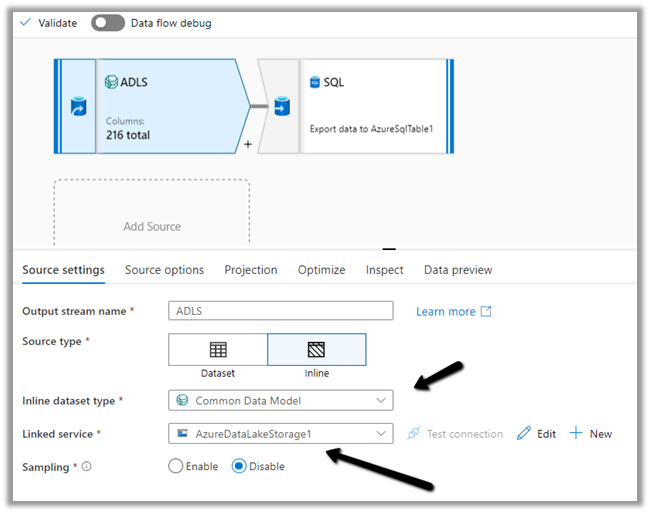
Source Option
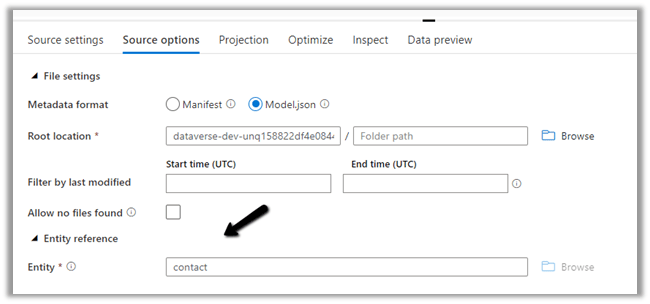
Specify the Dataverse folder for the Root Location.

Here we have specified the contact entity from our Data Lake Storage.
Projection
In the projection we have cleared the generated schema using Clear Schema, also selected Schema options >> Allow schema drift

We have enabled Allow schema drift option which will create the required columns in the destination Azure SQL Table.
Optimize

Inspect
Data preview
As we have not turned on Debug mode, there is nothing to preview
Now let us move to our Destination – SQL.
Sink
Here we have AzureSQLTable dataset connected to contact table in Azure SQL and have checked Allow schema drift option.

Below is our AzureSQLTable Dataset connected to the MyContacts table.
Settings
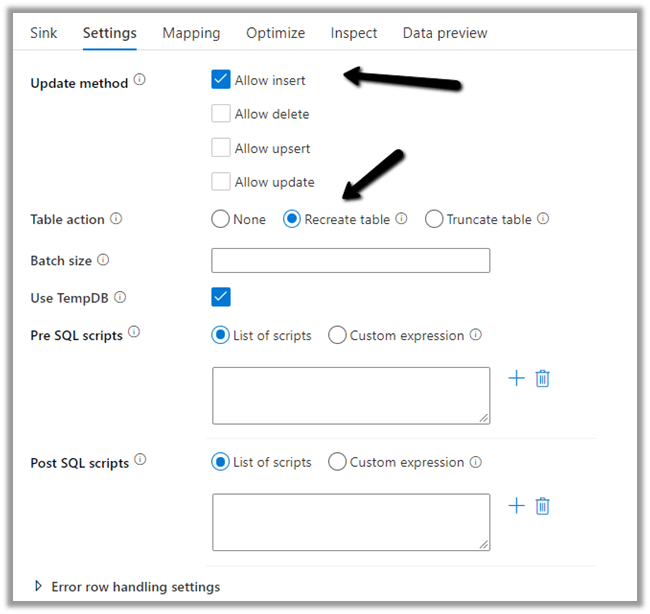
Here we have selected Allow Insert as the Update Method and Table
action as Recreate table – as we want the destination table to be re-created dynamically based on the source.

Mapping
We have left it to Auto mapping.
Optimize

Inspect

Data preview

Let us Publish All our changes and Debug our pipeline.

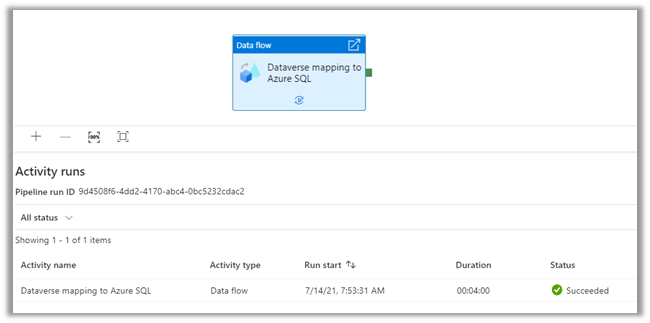
Let us monitor our pipeline run.

We can see that pipeline has run successfully and took around 4 minutes.
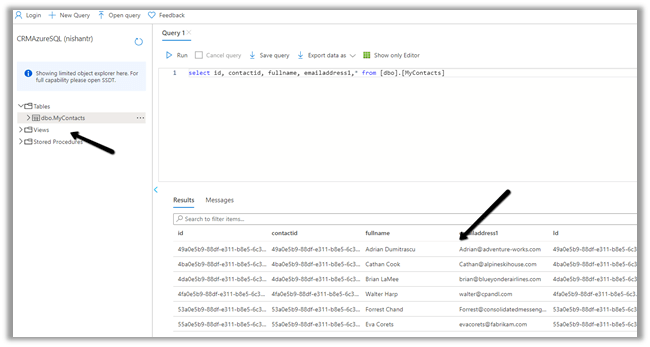
We can see the contact’s data copied to our Azure SQL successfully.
So here we covered the insert operation, in the next posts we’d see how we can configure update, upsert and delete operation.
Also, check
Hope it helps..
Discover more from Nishant Rana's Weblog
Subscribe to get the latest posts sent to your email.


Hi Nishant
I’ve got stuck at setting root location in the data flow. Have you ever come across this error?
—> ADLS Gen2 operation failed for: Operation returned an invalid status code ‘NotFound’. Account: ‘storageaccounttesting22’. FileSystem: ‘dataverse-athena05-unq106375223f9140d1b6cdbf6e35648’. ErrorCode: ‘FilesystemNotFound’. Message: ‘The specified filesystem does not exist.’. RequestId: ’11c52907-501f-0054-3906-99d261000000′. TimeStamp: ‘Tue, 24 Aug 2021 16:40:49 GMT’. Operation returned an invalid status code ‘NotFound’ Activity ID: 3c37de07-425b-4907-a419-738d5eed79ca
LikeLiked by 1 person
Thanks for that Nishant. I wish we could keep Data Export Service, the setup was so much easier, I can’t understand why they deprecated the service. Hopefully MS brings something more straightforward to be setup.
LikeLiked by 1 person
Ya that was easy straightforward
LikeLike
Thanks for your Post. How can I get the labels of the choises from dataverse? They are stored in the Microsoft.Athena.TrickleFeedService/table-EntityMetadata.json I tried to lookup this labels but it doesn’t work.
Thnaks in advance
LikeLiked by 1 person
Thanks Alexo for reading the post. Will check and let you know.
LikeLike
Good article. However, Data Export Service replicates data automatically upon update, delete or add events. Is that possible with ADF Pipeline too?
LikeLike
No that smooth as I can see. If you see the blog, it looks like they are recreating the table on copy ( if the users actively actively use azure sql for querying, they could experience downtime I suppose? Nishanth can you throw some light on this scenario what would be user experience?)
LikeLike
Hi Nishant, excellent post. We have an existing Azure SQL DB using DES we populate this from Dataverse, so if we replace the DES with Data Factory pipeline, we would want to keep the existing tables and views in this SQL DB intact and only map the data entities from ADLS to existing SQL DB tables and do an incremental updates, is that something that is possible?
LikeLiked by 1 person
Hi Omkar thanks for your kind words. Have not tried it, but I think should be possible. Will have to try it out and see, I am very new to this topic, I had just documented those few things which I had tried.
LikeLike
This seems to be quite expensive one. According to MS documentation “You pay for the Data Flow cluster execution and debugging time per vCore-hour. The minimum cluster size to run a Data Flow is 8 vCores”
LikeLike