For one of our projects, we were trying to figure out the optimum batch size and threads while using the CDS/CRM Destination component of KingswaySoft.
Now with Service Protection API limits in place, to get the maximum throughput the first point to consider is User Multiplexing.
Nicely explained here à
https://powerplatform.se/fast-data-management-in-a-limited-cds-world/
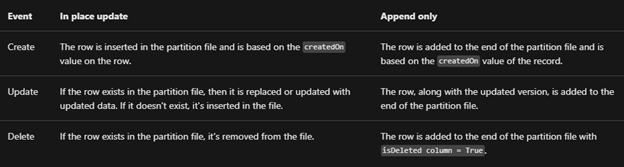
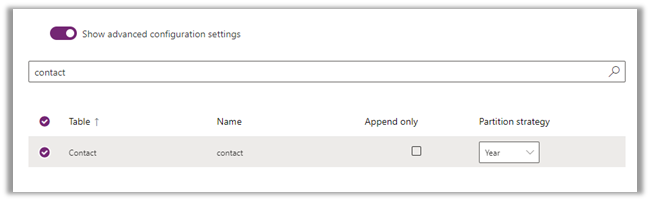
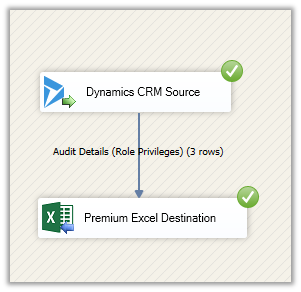
We are using the Conditional Split component to divide the load among the different CDS Destination Components which are running under different application users (using different CDS Connection Manager)
In the below data flow, we have 5 different CDS Destination components, each using a different Connection Manager configured using different users.

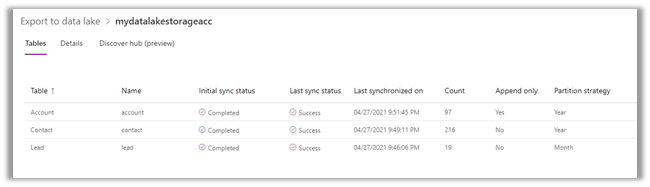
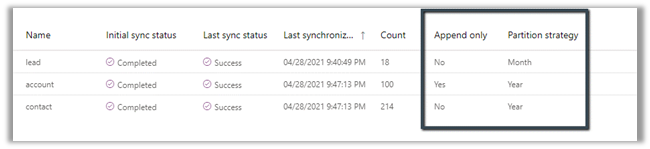
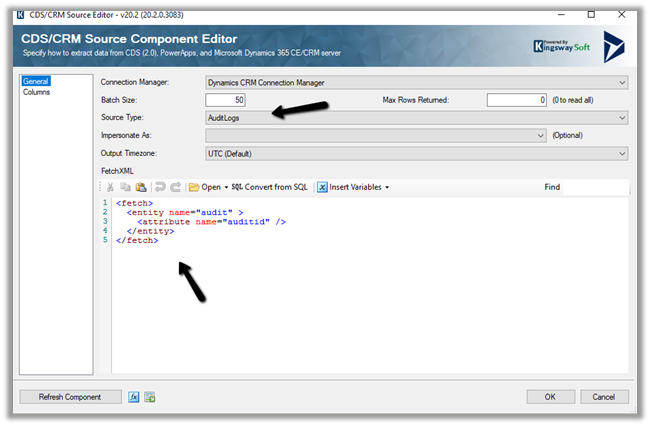
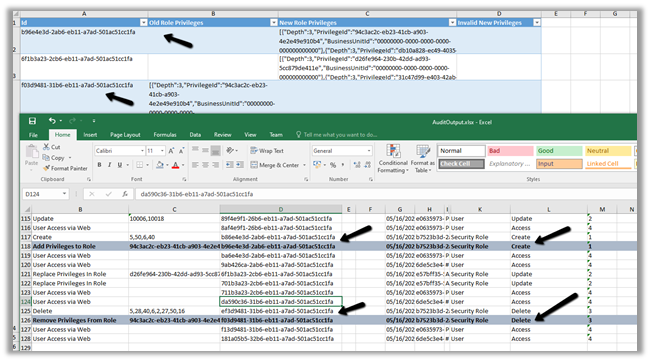
Here we took 50000 records as a sample for Contact – Create operation with 3 and 5
CDS Destination Component.
Below were our findings à
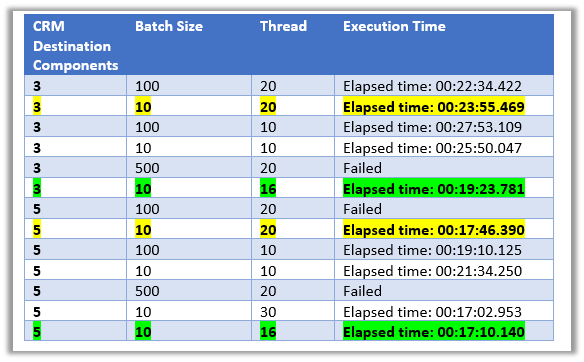
As suggested in the article, batch size as 10 and thread as 16 seem to give the best performance.

The trick is here to use as many threads as possible running under different users.
The CDS Destination component of KingswaySoft handles the server-side throttling automatically, it will follow the instruction and wait before trying again the same request.

On trying with 500 as the batch size, we got the error.

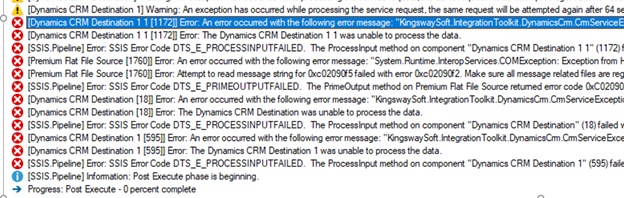
[Dynamics CRM Destination [18]] Error: An error occurred with the following error message: KingswaySoft.IntegrationToolkit.DynamicsCrm.CrmServiceException: CRM service call returned an error: The operation has timed out (Error Type / Reason: Timeout, Detailed Message: The operation has timed out) (SSIS Integration Toolkit for Microsoft Dynamics 365, v20.2.0.3083 – DtsDebugHost, 15.0.2000.128)KingswaySoft.IntegrationToolkit.DynamicsCrm.WebAPI.WebApiServiceException : The operation has timed out (Error Type / Reason: Timeout, Detailed Message: The operation has timed out)System.Net.WebException (Status Reason: Timeout): The operation has timed out”.
So basically try out the different combinations to get the maximum throughput.
Also check à
I think below will still be relevant but for CRM On-Premise
Batch Size and Copy of Paralleism for Azure Data Factory and Microsoft Dataverse
More articles on KingswaySoft and Dynamics 365 / Dataverse
https://nishantrana.me/2018/11/26/ssis-and-microsoft-dynamics-365/
Hope it helps..