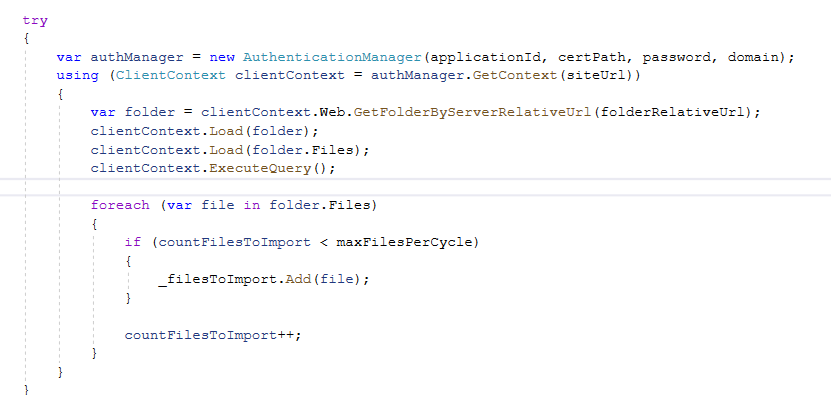
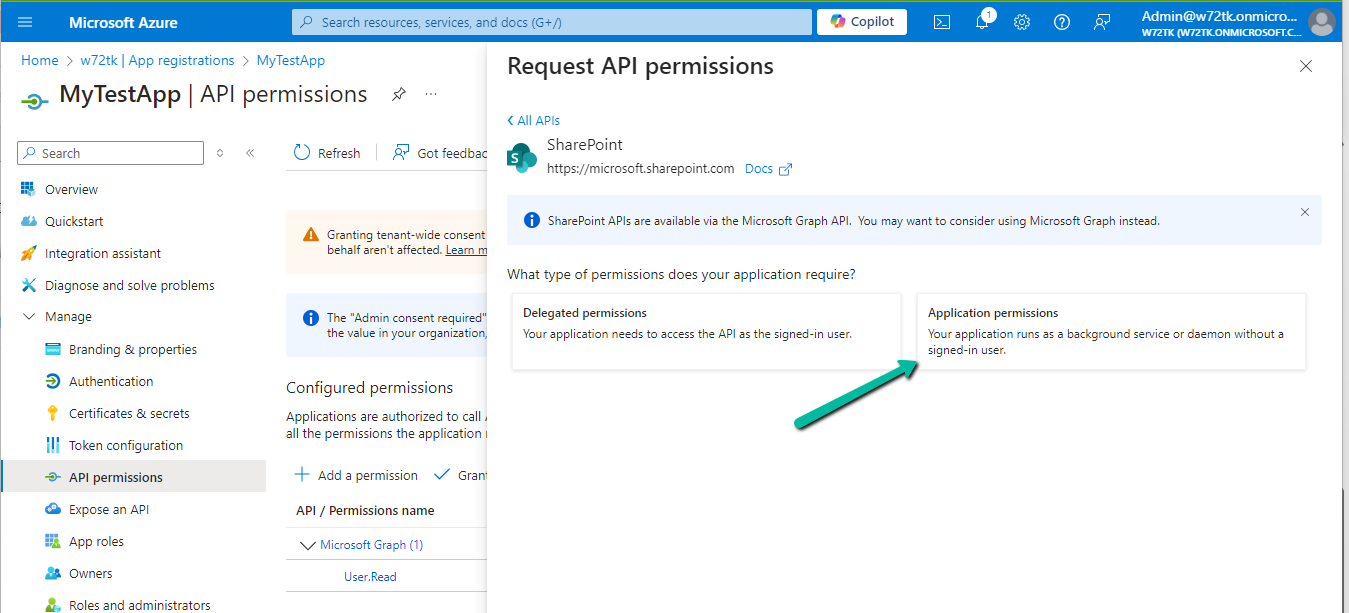
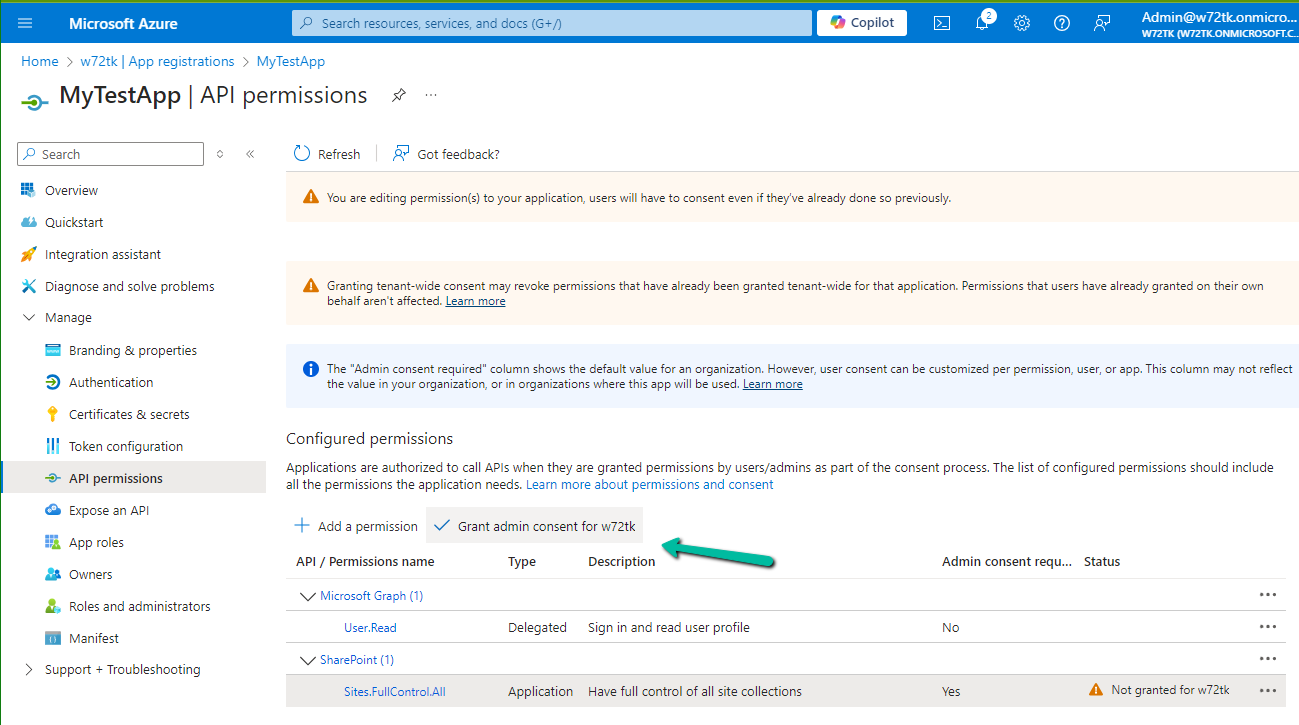
To enable Copilot for a specific instance of a Rich Text editor field, we first need to create a Web Resource where we need to specify the property we want to update/override as specified in the RTEGlobalConfiguration_Readonly.json, the base read-only configuration file for the Rich Text editor control.
We have created a JavaScript Web Resource file named rtecustom.js.
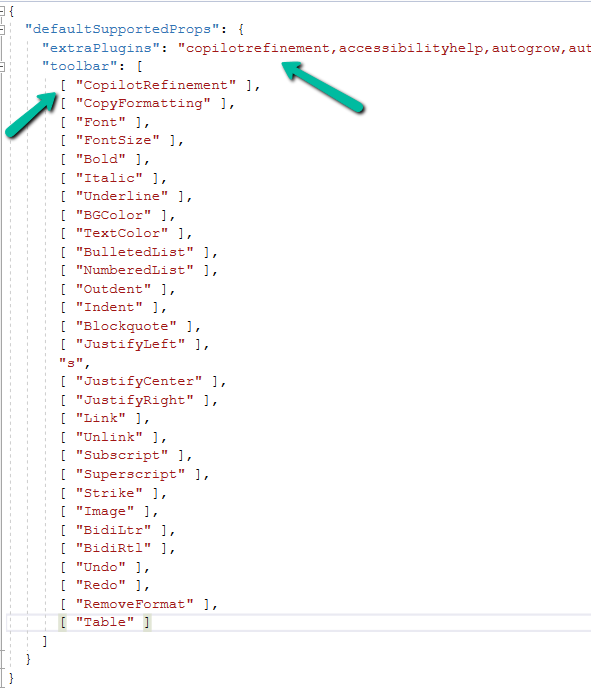
Added the copilitrefinement and CopilotRefinement values to the extraPlugins and toolbar properties existing values as shown to enable copilot.
Refer to the sample configuration file for all the properties and their corresponding values.
{
"defaultSupportedProps": {
"extraPlugins": "copilotrefinement,accessibilityhelp,autogrow,autolink,basicstyles,bidi,blockquote,button,collapser,colorbutton,colordialog,confighelper,contextmenu,copyformatting,dialog,editorplaceholder,filebrowser,filetools,find,floatpanel,font,iframerestrictor,indentblock,justify,notification,panel,panelbutton,pastefromword,quicktable,selectall,stickystyles,superimage,tableresize,tableselection,tabletools,uploadfile,uploadimage,uploadwidget",
"toolbar": [
[ "CopilotRefinement" ],
[ "CopyFormatting" ],
[ "Font" ],
[ "FontSize" ],
[ "Bold" ],
[ "Italic" ],
[ "Underline" ],
[ "BGColor" ],
[ "TextColor" ],
[ "BulletedList" ],
[ "NumberedList" ],
[ "Outdent" ],
[ "Indent" ],
[ "Blockquote" ],
[ "JustifyLeft" ],
[ "JustifyCenter" ],
[ "JustifyRight" ],
[ "Link" ],
[ "Unlink" ],
[ "Subscript" ],
[ "Superscript" ],
[ "Strike" ],
[ "Image" ],
[ "BidiLtr" ],
[ "BidiRtl" ],
[ "Undo" ],
[ "Redo" ],
[ "RemoveFormat" ],
[ "Table" ]
]
}
}
Note down the URL of the Web Resource created.

Next, we opened one of the Contact’s forms for Customization, selected the description field, and added the component – “Rich Text Editor Control” to it.

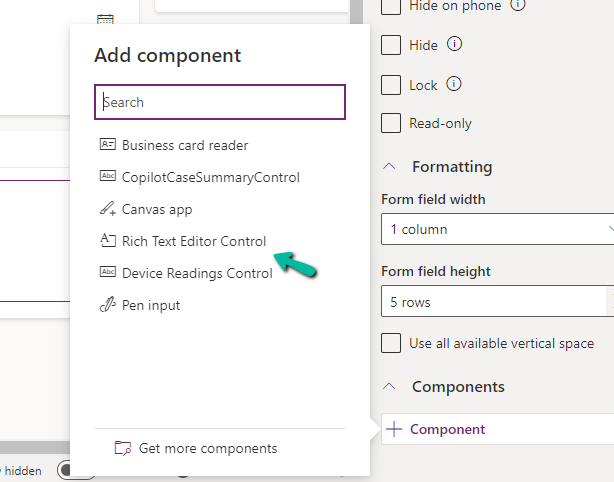
In the Static value property, we specified the relative URL of the Web Resource file. We can also specify the full path but then we would need to update it each time we move it to other environments.
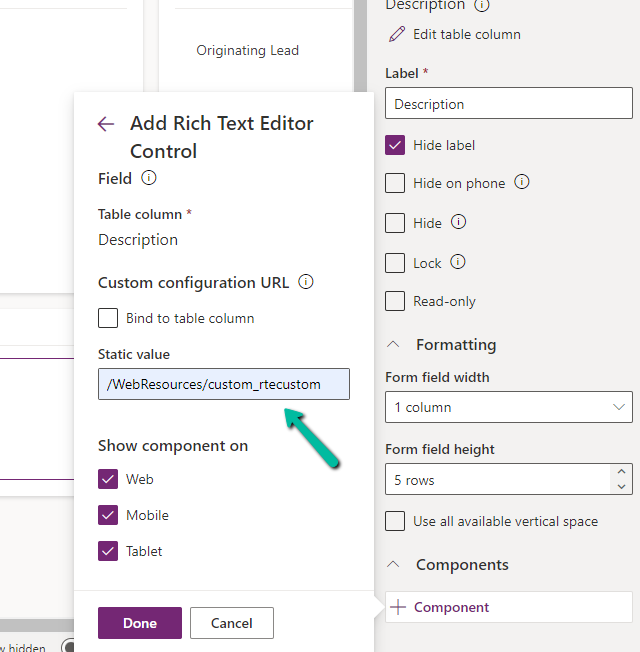
Save and publish the changes.
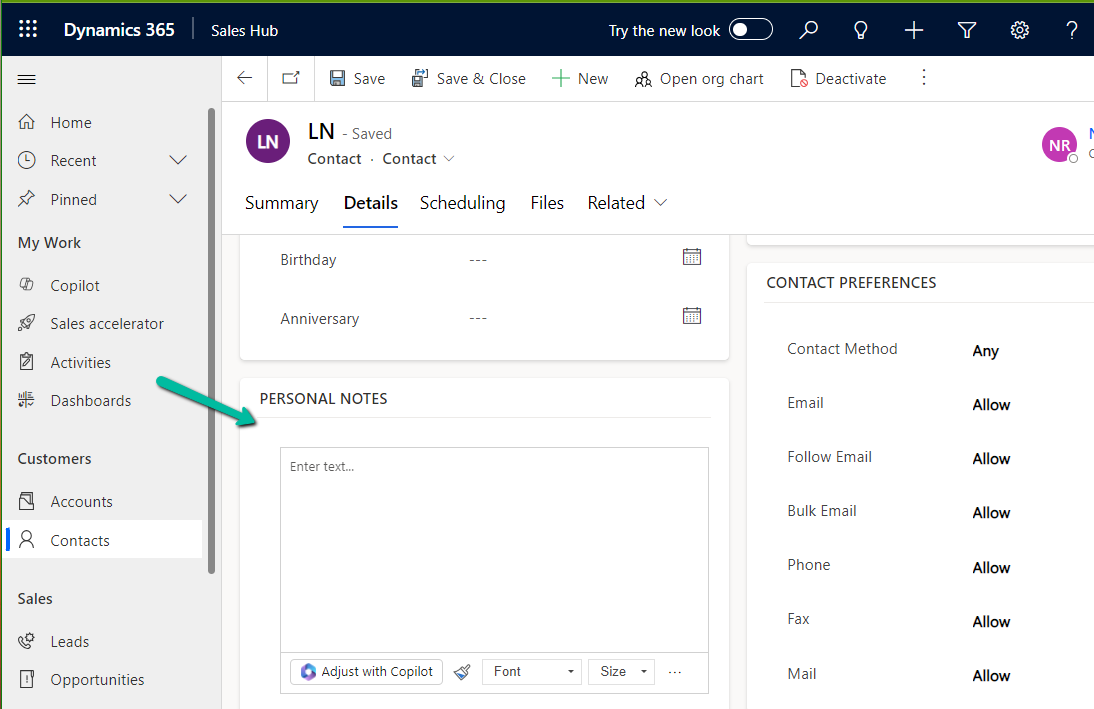
We can see the option Adjust with Copilot added to the toolbar for the control.
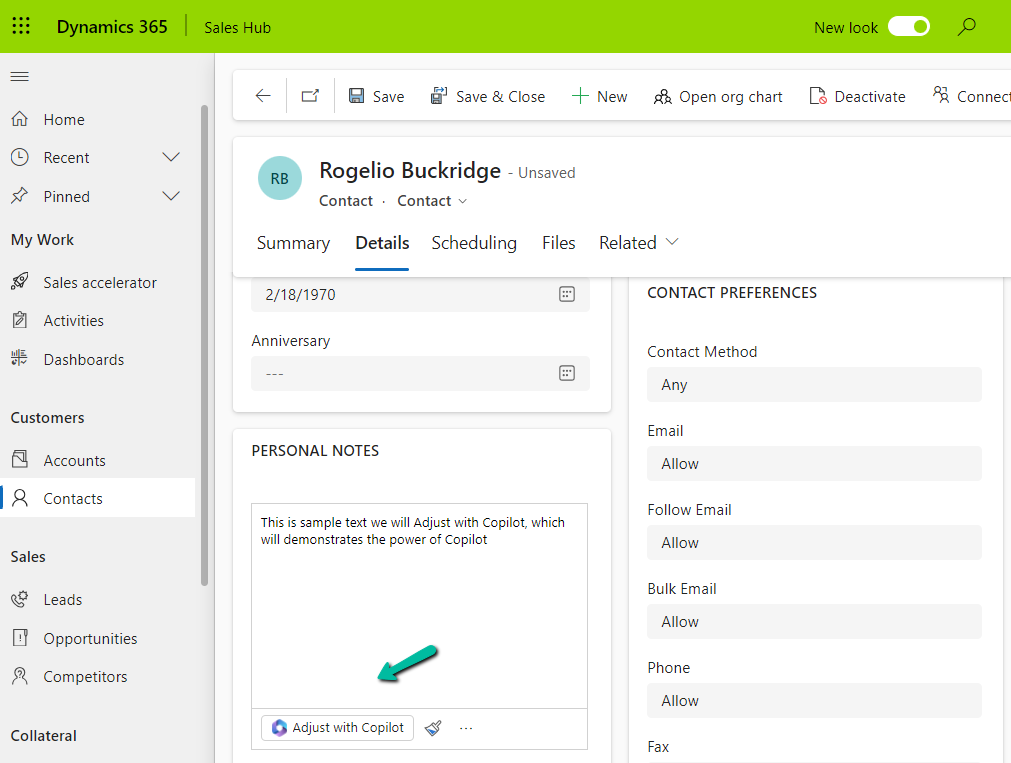
On selecting the text, and clicking on “Adjust with Copilot”, we get the option to update the Tone of the content.
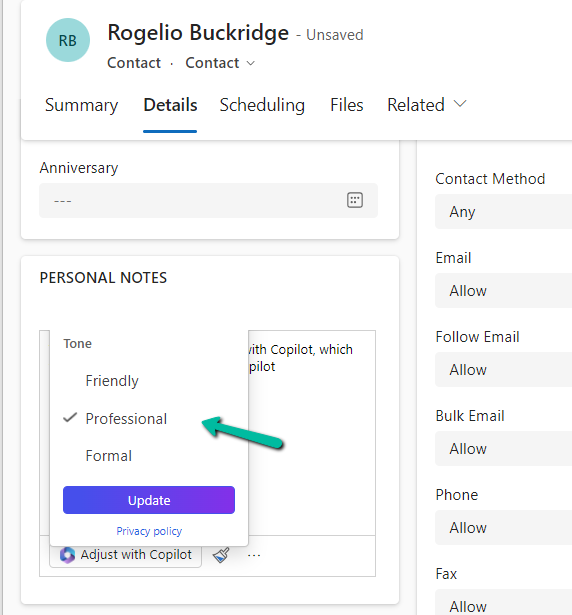
On selecting a Professional tone, the text is updated in the control.

In case we want to apply to all the fields that are using Rich Text Editor Control instead of specifying it for individual fields, we need to update and add the same JSON to the existing RTEGlobalConfiguration.json file.
The file is blank by default, and we can specify properties to it that we want to override.

We updated the RTEGlobalConfiguration.json file, to use the same definition we used earlier for our custom web resource.

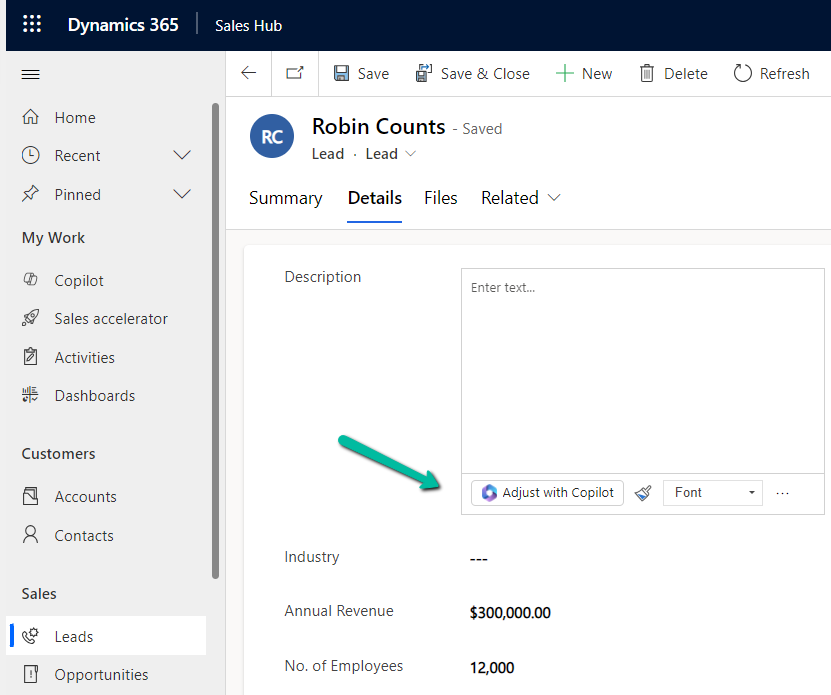
We can see the “Adjust with Copilot” added to the form even without specifying the URL in the static value while customizing the form.

On saving and publishing the changes, we can then see it rendered for all the Rich Text Editor fields.
Also, check – Copilot Control
Hope it helps..