In the previous post, we saw how to export CDS data to Azure Data Lake Gen 2
https://nishantrana.me/2020/09/07/export-data-from-common-data-service-to-azure-data-lake-storage-gen2/
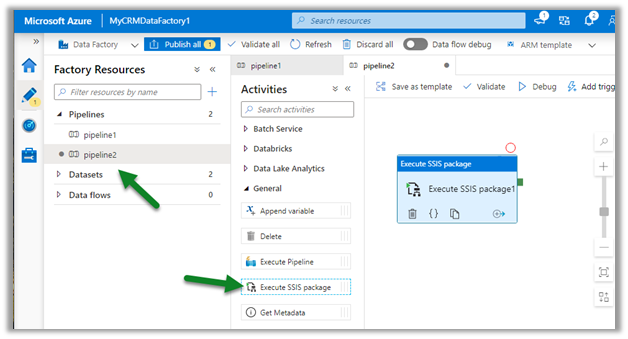
Here let us have a look how the sync and snapshot work.
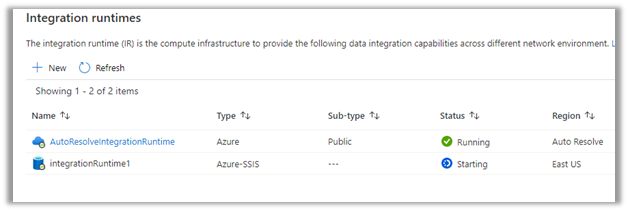
We have already done the configuration and have synced the Account and Contact entity.
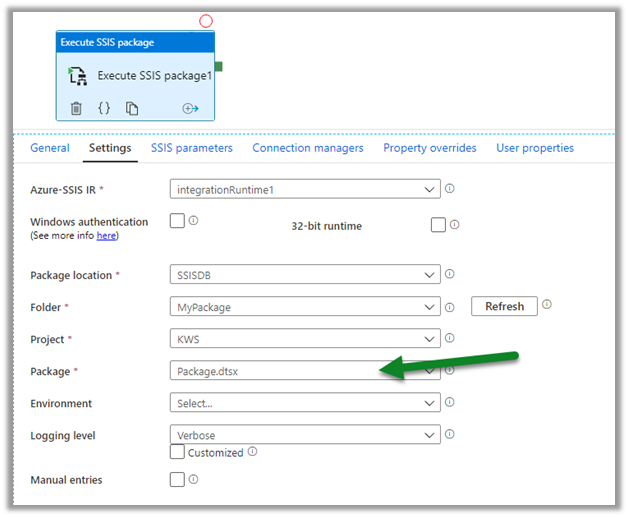
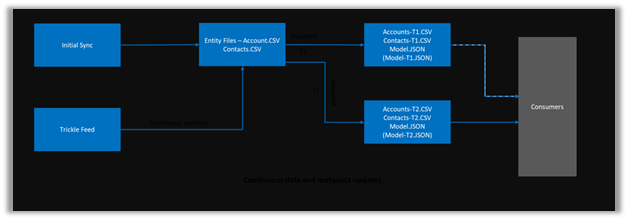
As the diagram depicts – there is initial sync followed by incremental writes for both entity data and metadata.
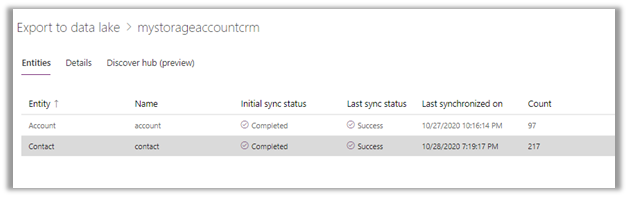
Below we can see we had initial sync completed for both contact and account entity, followed by an update in contact record which triggered another incremental sync – last synchronized on.
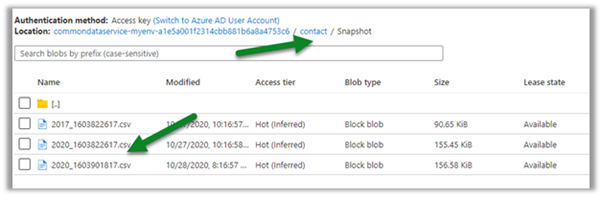
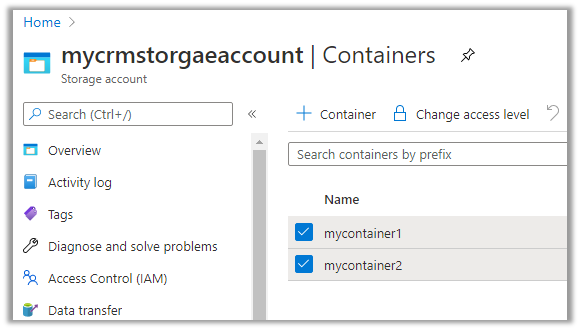
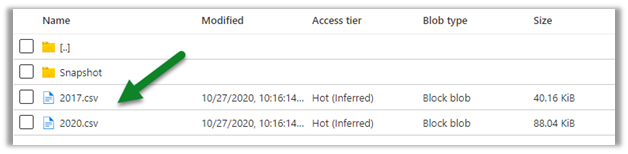
Within our storage container, we can see a folder created for each of the entities selected for sync.

As a part of initial sync or export, the entity data is written in CSV files
Changes in CDS are pushed to the CSV files continuously. (create, update and delete) along with a snapshot.
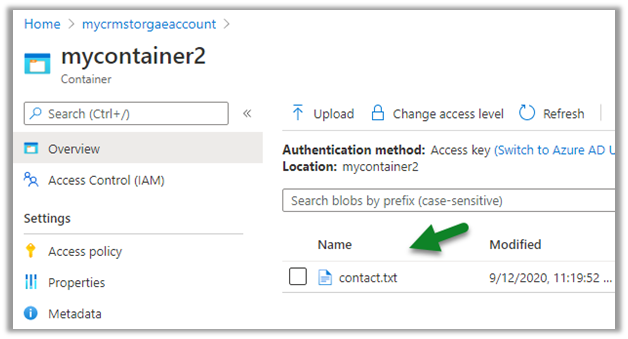
Within the Snapshot folder, we can see the snapshot added if there any change in the entity’s data.
Here for an account, we had no change.
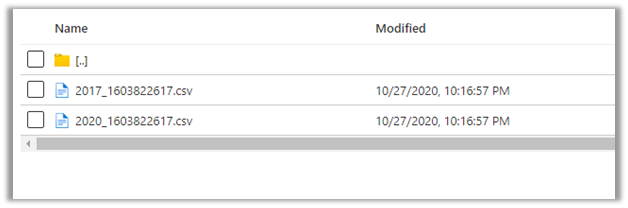
Now let us look at the contact entity, here we can see the update in the 2020.csv file.
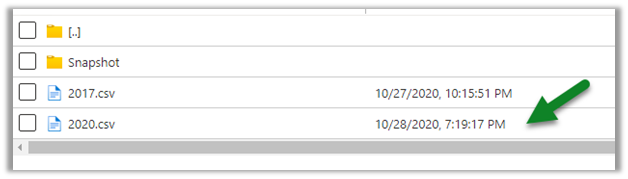
Let us look at the snapshot generated for contact; it shows no update as we have checked it within a 1-hour window of the update.
Snapshot is a read-only copy of data, which is updated at regular interval i.e. 1 hour, this ensures that the user is looking at a data which is not constantly getting refreshed.
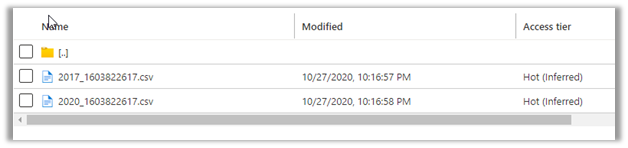
Refreshing after some time, we can see the new snapshot added for the Contact entity.

As expected, no new snapshot for the Account entity as there was no change.
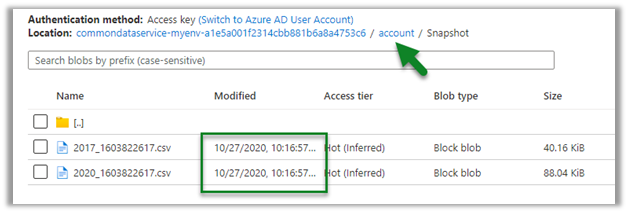
Let us create a new contact record, and see when we see the update in the CSV file and when does the new snapshot gets created.
We have created a new contact record around 8:30.
This was earlier before the update was made
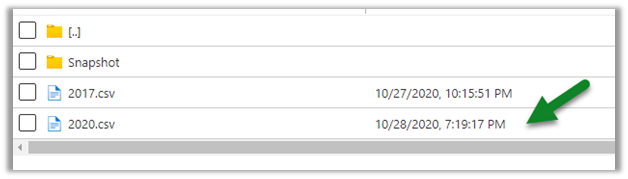
Within 5 minutes we can see the update in the CSV file
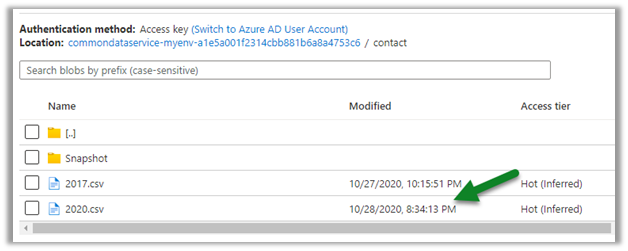
And as expected another snapshot at 9:16 exactly after one hour of the first snapshot.

Get all the details here
https://docs.microsoft.com/en-us/powerapps/maker/common-data-service/export-to-data-lake
Posts on Azure Data Lake
Hope it helps..