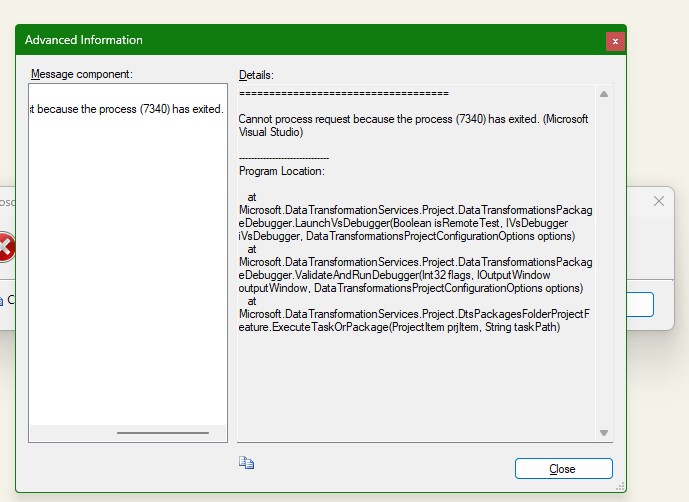
Hi,
Let us say we want to move data from Table named MyTable and view MyView from my SQL Server DB On-Prem to one of the Azure SQL Database.

The components involved here would be Publisher that publishes this data, Distributor that holds the information about the data to be published and Subscriber who subscribes to the data.
For Transaction Replication to work, the Azure SQL DB or any subscriber needs to have the matching schema as the published table. This can be achieved through Snapshot Agent which applies the snapshot. Distribution Agent distributes this snapshot to the Subscribers.
Transaction Replication Log Reader Agent looks for any changes in the published data. This agent runs at the distributor for “Push” subscriptions. It can run continuously and or can be scheduled. It looks for Insert, Update, Delete operations or any schema changes and pushes this to the Subscriptions.
Let us start by configuring the Distributor first. The distributor can be at the local or remote server.
We’d be creating a local Distributor here.
Right-click the Replication and select Configure Distribution


We are using the local server as Distributor.

Click Next.


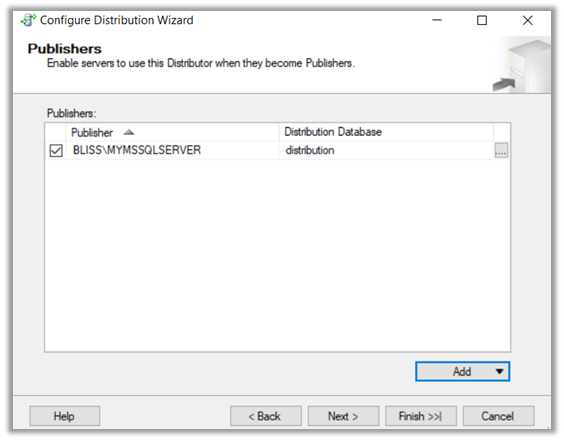
Click Finish to complete the wizard.

This creates the distribution database in our Local Server.

Now let us configure the Publication.
Right-click the publication and select new publication. SampleDB is the DB from whose table and view we want to publish.
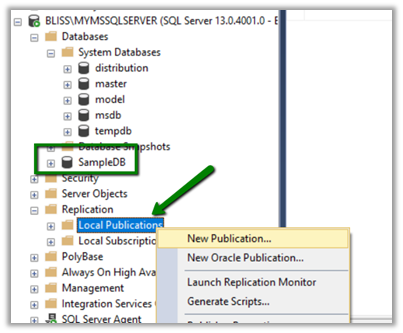
Select SampleDb
Select Transactional Publication

Select the table and the view
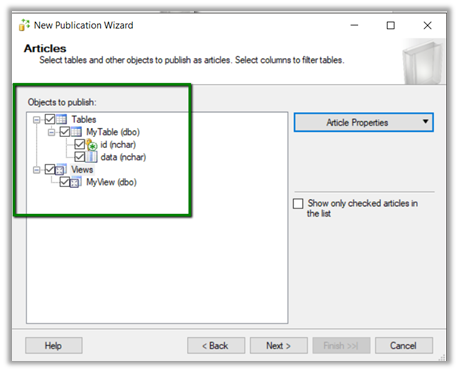
As we are publishing a view, we get the below message

We can click on Add to specify any filtering on the data to be published.

We can specify if we want to snapshot to be created immediately so that it is available while defining subscriptions. We can also schedule the Snapshot Agent or we can run it continuously.


Here we are specifying SQL Server Agent account.

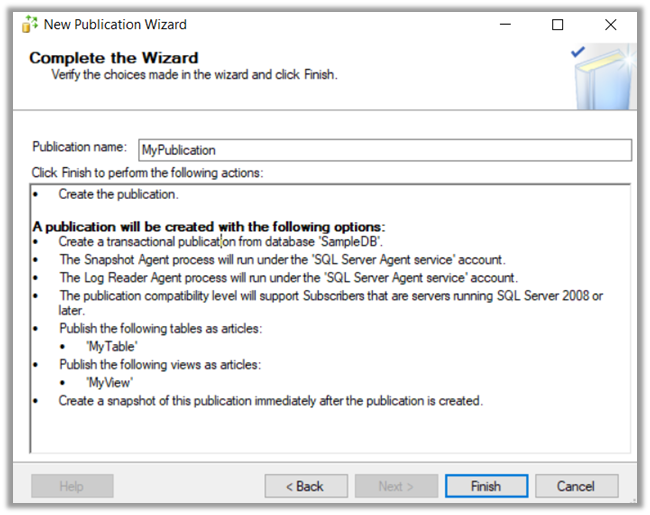
Specify Publication Name and click on Finish to create the publication.

Now let us create the Subscription.
Right-click the publication created earlier, and select new Subscription

Select the publication

We can specify the type of subscriptions either Push or Pull. In our case, we are selecting Push.

Select Add SQL Server Subscriber to add our Azure SQL DB as the subscriber here.

Connect to the Azure SQL DB.

Here MyDB is the Azure DB to which we want to push the data.


Now specify the account for the Distribution Agent and to connect the Azure SQL DB.
Select Agent schedule as Run Continuously.
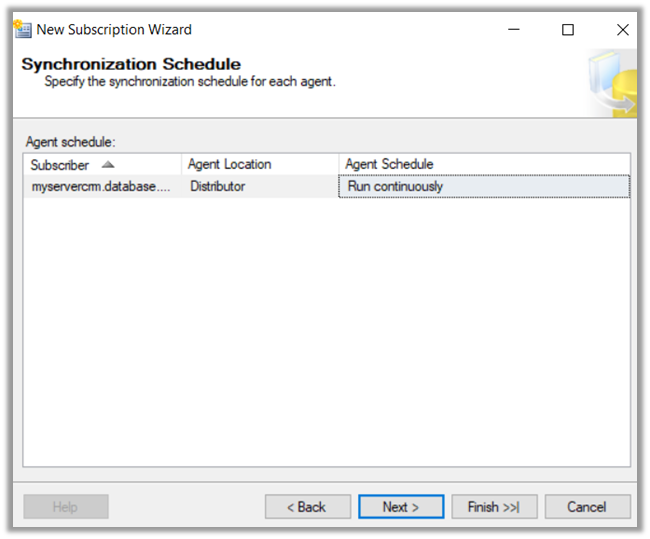
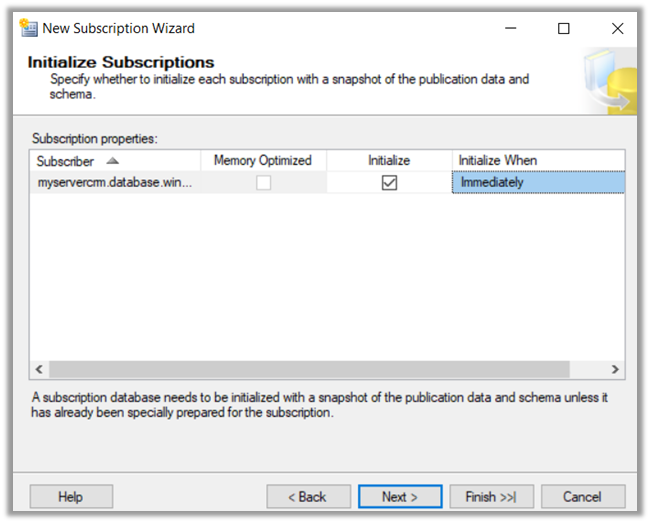
Click Finish to create the subscription.

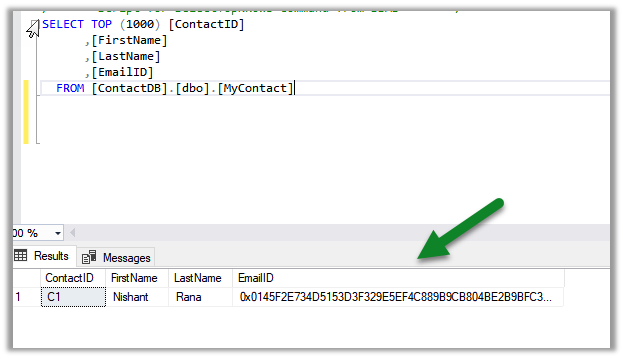
Back in our Azure SQL DB, we can see the table and the view created with the data.

In Job Activity Monitor, we can see the details.
REPL-LogReader, REPL-Distribution and REBP-Snapshot.

Now just to test it, let us add 2 new rows in our Sample DB’s MyTable.

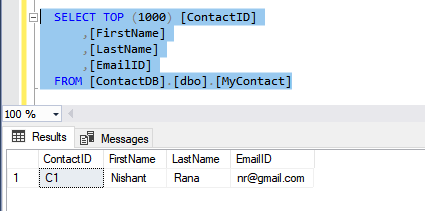
Back in our Azure DB, we can see the data being added to it.

More details below
https://www.pluralsight.com/courses/sqlserver-transactional-replication-fundamentals
https://docs.microsoft.com/en-us/sql/relational-databases/replication/publish/publish-data-and-database-objects
https://www.mssqltips.com/sqlservertip/5024/using-transactional-replication-with-an-azure-sql-database/
Hope it helps..